本記事では、Pandasのデータフレームの使い方をひと目で分かるように図解しながら、実行結果を『 print(“実行文 = “, 実行文) 』の形で掲載しています! どうぞご活用ください!
【画像クリックでスクロールします!】
目次
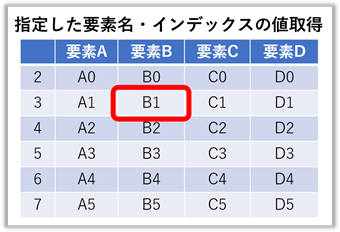
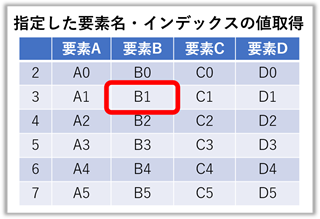
要素名とインデックスを指定した値の取得(行名と列名or列番号を指定)
右図の様にインデックス名に整数が使われている時は注意が必要です。
整数のまま使用すれば表を上から数えた順番に、【“”】で文字として扱えばインデックス名として扱われます。
※本項目では、説明のため故意にインデックス番号をずらしています。
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
2 A0 B0 C0 D0
3 A1 B1 C1 D1
4 A2 B2 C2 D2
5 A3 B3 C3 D3
6 A4 B4 C4 D4
7 A5 B5 C5 D5
frame["要素B"][1] = B1 # [1] = インデックスの “2番目” である 『x1』が取り出される
frame["要素C"][3] = C3
frame["要素C"]["3"] = C1 # ["3"] = インデックス名称の “3” の行である『x1』が取り出される
###### 列と行を順番に指定して取り出す場合 ######
""" 実行 """
df = frame["要素D"]
df = 2 D0
3 D1
4 D2
5 D3
6 D4
7 D5
Name: 要素D, dtype: object
df[2] = D2
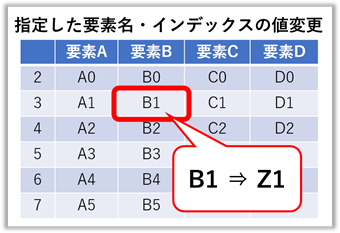
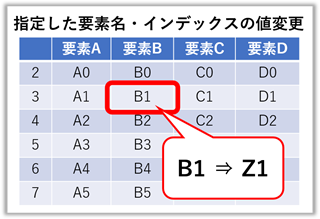
要素名とインデックスを指定した値の上書き
右図の様にインデックス名に整数が使われている時は注意が必要です。
整数のまま使用すれば表を上から数えた順番に、【“”】で文字として扱えばインデックス名として扱われます。
また、存在しない“要素名”を指定した場合はエラーが出ますが、存在しないインデックス番号ではエラーは出ずに無視されます。
※本項目では、説明のため故意にインデックス番号をずらしています。
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
2 A0 B0 C0 D0
3 A1 B1 C1 D1
4 A2 B2 C2 D2
5 A3 B3 C3 D3
6 A4 B4 C4 D4
7 A5 B5 C5 D5
""" 実行 """
frame["要素B"][1] = "Z1" # [1] = インデックスの “2番目” が指定される
frame["要素C"]["7"] = "Z2" # ["7"] = インデックス名称の “7” が指定される
frame["要素C"]["10"] = "Z3" # ["10"] = 存在しないので、無視される
""" 結果 """
frame = 要素A 要素B 要素C 要素D
2 A0 B0 C0 D0
3 A1 Z1 C1 D1
4 A2 B2 C2 D2
5 A3 B3 C3 D3
6 A4 B4 C4 D4
7 A5 B5 Z2 D5
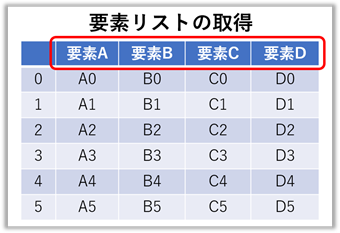
要素リスト(列名リスト)の取得
【ポイント!】:『 .tolist() 』で即時リスト化が可能です。
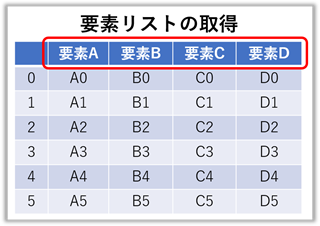
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
frame.columns = Index(['要素A', '要素B', '要素C', '要素D'], dtype='object')
# ( type(frame.columns) = <class 'pandas.core.indexes.base.Index'> )
frame.columns.tolist() = ['要素A', '要素B', '要素C', '要素D']
# ( type(frame.columns.tolist()) = <class 'list'> )
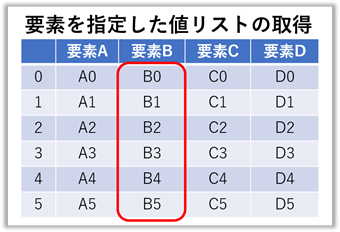
要素を指定した列 (カラム:Column) の値取得
【ポイント!】:『 .tolist() 』で即時リスト化が可能です。
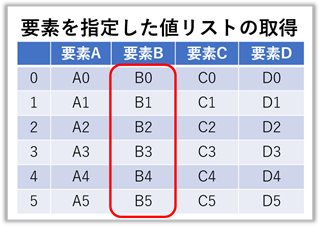
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
frame["要素B"].tolist() = ['B0', 'B1', 'B2', 'B3', 'B4', 'B5']
# ( type(frame["要素B"].tolist()) = <class 'list'> )
frame["要素C"] = 0 C0
1 C1
2 C2
3 C3
4 C4
5 C5
Name: 要素C, dtype: object
# ( type(frame["要素C"]) = <class 'pandas.core.series.Series'> )
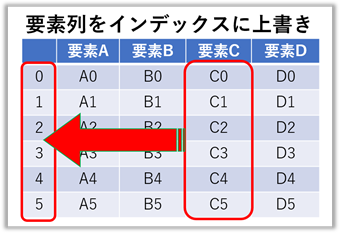
特定の要素の列をインデックスに指定(上書き)する
【ポイント!】インデックス化した要素列は削除されます。
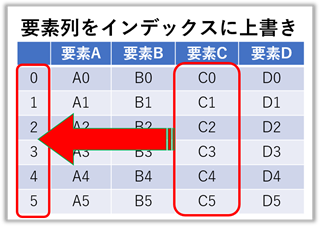
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
""" 実行 """
frame.set_index("要素C", inplace = True)
frame = 要素A 要素B 要素D
C0 A0 B0 D0
C1 A1 B1 D1
C2 A2 B2 D2
C3 A3 B3 D3
C4 A4 B4 D4
C5 A5 B5 D5
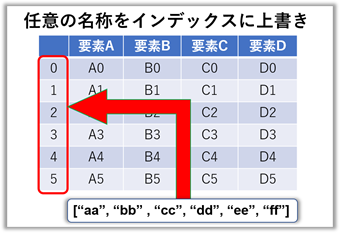
項目名・インデックス名を任意の名称に上書きする
【ポイント!】既存のインデクスと長さが違うとエラーです。(長・短どちらも)
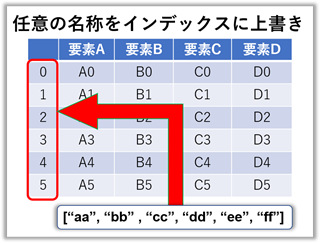
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
""" 実行 """
frame.index = ["aa", "bb", "cc", "dd", "ee", "ff"]
frame = 要素A 要素B 要素C 要素D
aa A0 B0 C0 D0
bb A1 B1 C1 D1
cc A2 B2 C2 D2
dd A3 B3 C3 D3
ee A4 B4 C4 D4
ff A5 B5 C5 D5
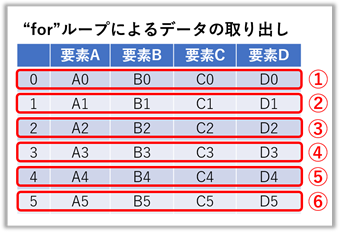
データフレームから “ for ” ループによるデータの連続取り出し
【ポイント!】DataFrameをそのまま for 文で回すと要素名のみが出力されてしまいます。
よってここでは “ itertuples() ” と “ iterrows() ” を使用して取り出す方法を例に挙げます。
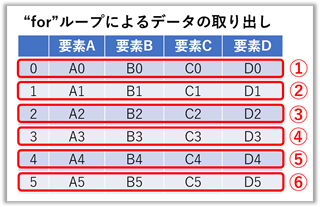
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
################################################
""" 実行 """
for indep_f in frame.itertuples():
print("indep_f = ", indep_f)
""" 結果 """
indep_f = Pandas(Index=0, 要素A='A0', 要素B='B0', 要素C='C0', 要素D='D0')
indep_f = Pandas(Index=1, 要素A='A1', 要素B='B1', 要素C='C1', 要素D='D1')
indep_f = Pandas(Index=2, 要素A='A2', 要素B='B2', 要素C='C2', 要素D='D2')
indep_f = Pandas(Index=3, 要素A='A3', 要素B='B3', 要素C='C3', 要素D='D3')
indep_f = Pandas(Index=4, 要素A='A4', 要素B='B4', 要素C='C4', 要素D='D4')
indep_f = Pandas(Index=5, 要素A='A5', 要素B='B5', 要素C='C5', 要素D='D5')
# ( type(indep_f) = <class 'pandas.core.frame.Pandas'> )
################################################
""" 実行 """
for indep_f in frame.iterrows():
print("indep_f = ", indep_f)
""" 結果 """
indep_f = (0, 要素A A0
要素B B0
要素C C0
要素D D0
Name: 0, dtype: object)
indep_f = (1, 要素A A1
要素B B1
要素C C1
要素D D1
Name: 1, dtype: object)
indep_f = (2, 要素A A2
要素B B2
要素C C2
要素D D2
Name: 2, dtype: object)
### 以下、index = 5 のデータまで
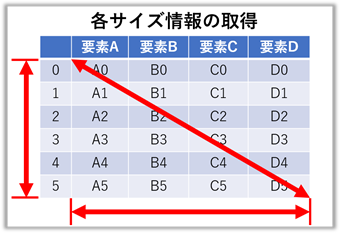
# ( type(indep_f) = <class 'tuple'> )DataFrameのサイズ情報の取得
【ポイント!】『 .shape 』で取得したデータを使うのが一番早そうです。
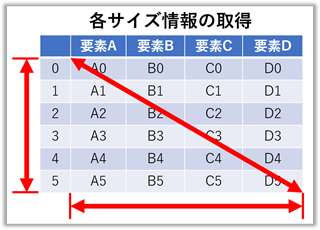
### print("実行文 = ", 実行文) の結果 ###
frame = 要素A 要素B 要素C 要素D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
frame.shape = (6, 4) # ( インデックス数, 項目数 )
frame.size = 24 # 全セル数
len(frame) = 6 # インデックスの長さ
len(frame.columns) = 4 # 項目の数